Estamos adaptados a ver películas de ficción donde el mundo es invadido por robots que, en nuestra ignorancia, o sed de grandeza, hemos creado con la ilusión de poder generar inteligencia.
Esa esperanza y ansias de ver estos logros de la tecnología, se ve frenada ante el hecho de imaginar que se puede salir de control, y que nos podamos ver en peligro si llegasen a tener la capacidad de razonar.
Todo esto la mayoría de las personas hoy en día lo ve como algo lejano. Sin saber, que cada día estamos más cerca de muchas de las cosas que vemos en películas de ciencia ficción de hoy, pero que se harán realidad, e incluso muchas de ellas ya lo son.
Os dejo una serie datos francamente curiosos, que seguramente os hará reflexionar.
Se estima que 4 exabytes de información serán generados este año. Eso es más que en los 5000 años anteriores.
En estos momentos estamos preparando estudiantes para trabajos que todavía no existen, usando tecnologías que no se terminan de inventar, y resolver así, problemas que ni siquiera sabemos que lo son.
La cantidad de información técnica se duplica cada 2 años. Para estudiantes que comienzan una carrera técnica de 4 años, esto significa, que la mitad de lo que ellos aprendan en el primer año de estudio estará desactualizado al tercer año.
Estamos viviendo en tiempos exponenciales. Hay 31 billones de búsquedas en Google cada mes. En 2006 este número era de 2,7 billones.
Las predicciones dicen que para el año 2049 un computador de 1000$ excederá las capacidades computacionales de toda la especie humana.
Entonces mi pregunta es: ¿Qué significa todo esto?
Significa que hay que asumir con total naturalidad los nuevos tiempos, e intentar entender todos estos conceptos que comentaba al inicio del artículo, porque cada vez serán más nuestra realidad.
Tenemos que ver la inteligencia artificial como un aliado que nos puede ayudar a ampliar el alcance de nuestros sentidos, convirtiéndonos en superhumanos, o al menos, poder lidiar de manera natural con toda esta información. De ahí, la importancia de la convergencia entre la inteligencia humana y la artificial.
Es este artículo, intentaré hacer un paralelismo entre la inteligencia de la mente humana y la inteligencia artificial.
La inteligencia artificial surge para simular las capacidades que son exclusivas del ser humano, y una manera de lograrlo, es intentar replicar el funcionamiento del cerebro humano. Para esto se crean las redes neuronales, que intentan recrear el comportamiento de las neuronas biológicas cerebrales.
En la siguiente imagen se muestra cómo las redes neuronales artificiales simulan a las neuronas cerebrales.
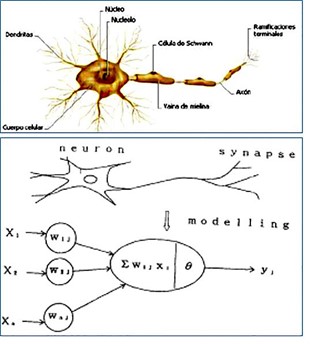
Comencemos por lo sencillo. La unidad más simple está inspirada en la célula principal del sistema nervioso, la neurona.
Su funcionamiento se basa en la conectividad que presentan. Sin embargo, la neurona artificial es mucho más sencilla. Consiste en un modelo simplificado de la neurona real, pero contiene los elementos básicos que le permiten realizar actividades lógicas.
Cada neurona consta de un cuerpo celular o soma, el árbol de ramificaciones o dendritas y el axón. La información entra por las dendritas, que es procesada en el soma, y finalmente sale por el canal de salida, el axón.
La idea es replicar muchas neuronas y crear una red neuronal. Ésta, se auxiliará de un algoritmo que intentará simular las funciones cognitivas de nuestro cerebro, para resolver problemas y poder aprender. Mientras más conexiones se puedan crear, más podrá experimentar.
Al igual que hace el hombre para resolver situaciones, la IA acudirá a la experiencia acumulada, y para esto necesita mucha información con la que aprender, de ahí la importancia de los datos.
Existe una diferencia importante entre ambas. Nuestro cerebro tiene millones de ramificaciones interconectadas que no siguen un orden lógico, mientras que la artificial, presenta un orden estricto y perfectamente organizado para que la información viaje de un lugar a otro.
Pero ¿cómo podemos imitar el comportamiento de la neurona? En 1949 se crea un modelo que calcula el peso de la conexión neuronal y que funciona de la siguiente manera:
Las señales que entran a la neurona estarán ponderadas o asociadas a un peso (parámetro), que podrá ser positivo o negativo. Si es positivo, es como si la neurona se excitase y si es negativo como si se desinhibiera. Finalmente, se suman las entradas ponderadas y si esa suma es mayor que el umbral de la neurona, entonces se activa.
Si entendemos la base antes explicada, entonces estamos en condiciones de comprender la red neuronal que se basa en la unión de estos componentes.
Para entenderlo de manera sencilla, muestro una imagen con una arquitectura de red simple.
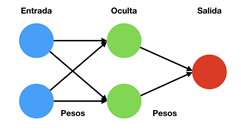
Se compone de una capa de entrada, otra capa oculta y una capa de salida. Entre cada capa se definen los pesos y la función de activación para las neuronas. Éstas pueden ser diferentes entre cada una de las capas.
Llega un punto, que cuando el número de capas ocultas crece, la complejidad también aumenta, y es entonces cuando nacen las redes neuronales profundas (
Deep Learning).
La mayoría de los métodos de
Machine Learning emplean arquitecturas neuronales. De esta forma, las arquitecturas de
Deep Learning emplean diferentes modelos de redes neuronales como:
Deep Neural Network (DNN) o Redes neuronales profundas
Convolutional Neuronal Network (CNN) o Redes neuronales profundas convolucionales
Deep Belief Network (DBN) o Redes de creencia profundas
En este artículo nos centraremos en las redes neuronales convolucionales. Éstas son especialmente buenas para la detección y categorización de objetos, o clasificación y segmentación de imágenes. Se basa en un algoritmo que tiene la característica de utilizar variantes de una red neuronal tradicional, y las combina con el comportamiento biológico del ojo humano, para lograr aprender a ver.
Para que las redes convolucionales funcionen, necesitan una operación de convolución. De esta forma, se aprenden las características de orden superior.
Pero, ¿qué es la operación de convolución?
Mostremos un ejemplo sencillo.
Les presento a la gatita Missi. Ella será nuestra compañera con la que podremos entender mejor una red neuronal profunda.
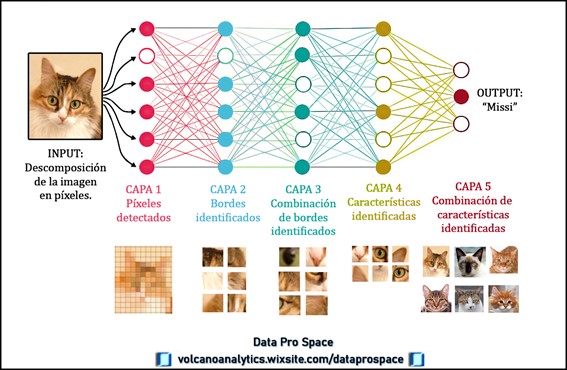
Este tipo de red usará la imagen de entrada para aprender la relación que tiene con la salida.
La imagen se filtra usando una máscara, y la descompone en píxeles. Con las máscaras, podemos representar las conexiones entre las neuronas y las capas previas. Si usamos diferentes máscaras, obtendremos distintos resultados.
La idea entonces es ir aprendiendo de manera progresiva las características de la capa anterior.
Al pasar de la capa número uno a la capa número dos, con la primera convolución, identificamos características más primitivas, como líneas, curvas y bordes de la cara de la gatita. Al pasar de la capa dos a la tres, se mostrarán la combinación de estos bordes.
Sucesivamente, al pasar de la capa tres a la capa cuatro, ya podremos distinguir características como los ojos, orejas, boca, etc. Y finalmente, en la última capa, se combinan todas estas características identificadas y obtenemos la salida con la identificación de Missi.
Esto es solo un ejemplo que ayudará a entender el proceso de manera general. Y aunque se quedan muchas cosas en el tintero, este artículo puede ser un punto inicial para profundizar en el tema, y aprender sobre este apasionante mundo.
Si eres aún más arriesgado y tienes algún conocimiento más avanzado del tema, te invito a que visites un artículo de corte más técnico que se encuentra en el blog
VolcanoAnalytic
Si te ha servido no dudes en compartirlo.
¡Gracias y buena suerte! ;)