Son básicamente 3 tipos de transformaciones:
- Análisis de texto (text analytics): que utiliza la API de servicios cognitivos.
- Visión (vision): también utiliza la API de servicios cognitivos.
- Aprendizaje automático (azure machine learning): expone sus funciones / modelos de Azure Machine Learning.
Sucede que un requisito súper importante para usar cualquiera de ellas es que necesitas tener una capacidad Premium en uno de sus espacios de trabajo para poder utilizarlas.
Pero ¿qué tal si les digo que esta capacidad la podemos obtener de manera gratuita con Python?
Sí señores, podemos hacer
Machine learning de manera relativamente sencilla con Python en Power BI y sin necesidad de ser premium.
Python con Power BI va mucho más allá del proceso de ETL y está creando una gran adición a la familia Power BI, al proporcionarle la capacidad de realizar importación, transformación de datos rápida o crear visualizaciones de datos interesantes. Pero va mucho más allá, e incluso puede expandir aún más sus informes al incorporar aprendizaje automático e IA.
En este post veremos un ejemplo sencillo de cómo podemos hacer
Machine Learning usando este lenguaje tan popular.
Partiremos del uso de un Dataset muy conocido. El dataset del titanic. Intentaremos predecir la supervivencia y probabilidades de sobrevivir en este catastrófico suceso.
Realizaremos un ejemplo sencillo de aprendizaje supervisado y clasificación binaria. (1 – pasajero sobrevive / 0 – pasajero muere)
Antes de comenzar debemos asegurarnos de que el conjunto de prueba reúna las siguientes dos condiciones:
- Que sea lo suficientemente grande como para generar resultados significativos desde el punto de vista estadístico.
- Que sea representativo de todo el conjunto de datos. En otras palabras, no elijas un conjunto de prueba con características diferentes al del conjunto de entrenamiento.
Finalmente, si el conjunto de prueba reúne estas dos condiciones, tu objetivo es crear un modelo que generalice los datos nuevos de forma correcta.
Nota: Nunca uses los datos de prueba para el entrenamiento. Si ves resultados sorpresivamente positivos en tus métricas de evaluación, es posible que estés usando los datos de prueba para el entrenamiento. Por ejemplo, tener una precisión muy alta puede ser un indicativo de que se filtraron datos de prueba en los de entrenamiento.
Analicemos los datos, (ver Fig.1)
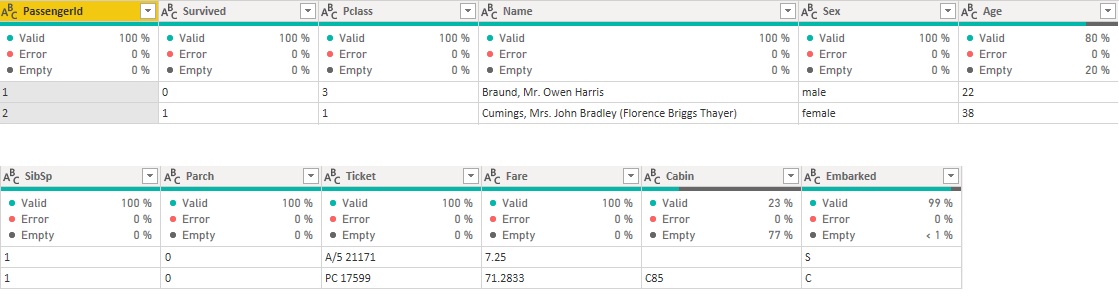
Tenemos 1309 registros y 12 características, incluyendo nuestra variable objetivo (Survived).
Las variables que me servirán para predecir en el modelo.
SibSp - # de hermanos / cónyuges a bordo del Titanic
Parch - # de padres / hijos a bordo del Titanic
Embarked - Puerto de embarque
Fare - Tarifa de pasajero
Age - Edad
Sex - Sexo
Pclass - Clase
Survived - Sobrevivió (1 sobrevive - 0 no sobrevived
Vemos que nuestros datos son una combinación de categorías y números. Lo que significa, que deberemos codificar los datos categóricos para presentarlos como números, con el objetivo de que nuestro modelo de aprendizaje automático pueda trabajar correctamente con ellos.
A continuación, muestro una serie de transformaciones y limpieza de datos pertinentes, así tendremos los datos listos para trabajar.
Transformaciones
Una vez en el editor de consultas realizaré las siguientes transformaciones.
1- Elimino la columna Cabin porque tiene muchos datos vacíos y no me es significativa para el análisis.
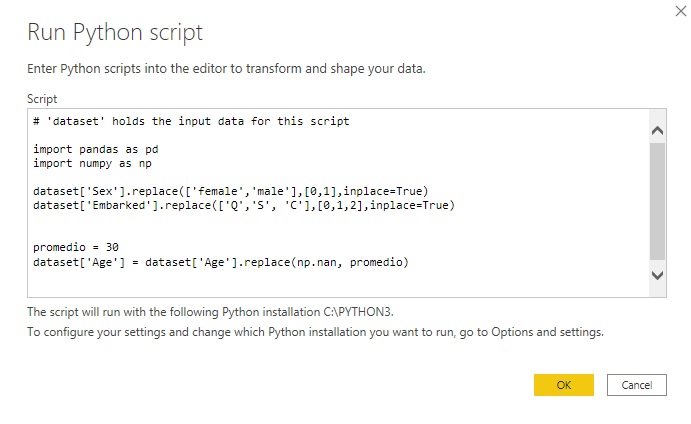
2- Las transformaciones que haremos a continuación son realizadas mediante script de Python (ver Fig.2)

Se abrirá una ventana (ver Fig.3) donde copiaremos el siguiente código.
# se importan las librerias necesarias
import pandas as pd
import numpy as np
# se reemplaza el sexo por femenino(0), masculino(1)
dataset['Sex'].replace(['female','male'],[0,1],inplace=True)
# se reemplaza la puerta de embarque por números Q(0), S(1), C(2)
dataset['Embarked'].replace(['Q','S', 'C'],[0,1,2],inplace=True)
# se calcula la media de la edad
promedio = dataset['Age'].mean()
# se inserta la media de la edad en los datos vacíos de la columna
dataset['Age'] = dataset['Age'].replace(np.nan, promedio)
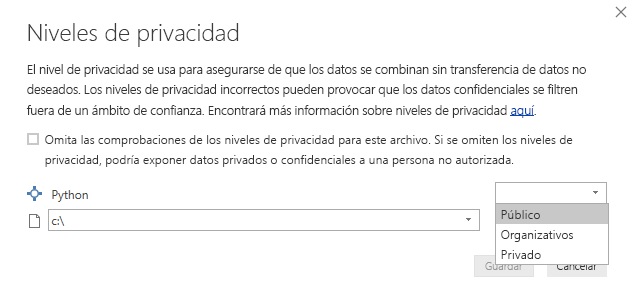
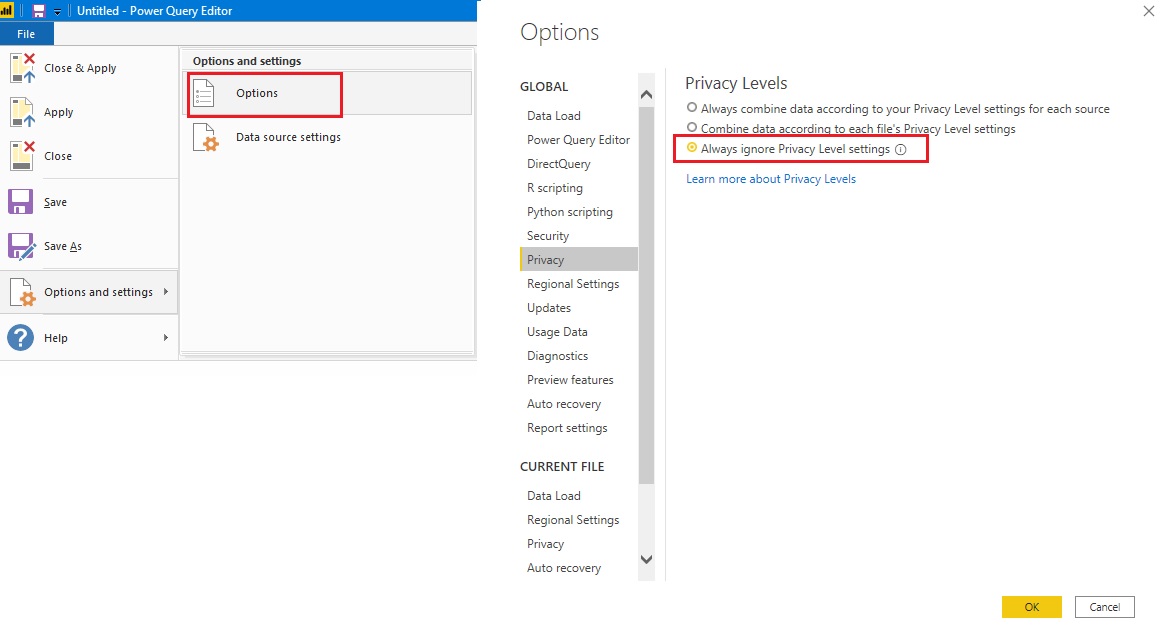
3- Después de seleccionar OK (Aceptar), el Editor de consultas muestra una advertencia sobre la privacidad de datos. Para que los scripts de Python funcionen correctamente en el servicio Power BI, todos los orígenes de datos se deben establecer como públicos (ver Fig.4).
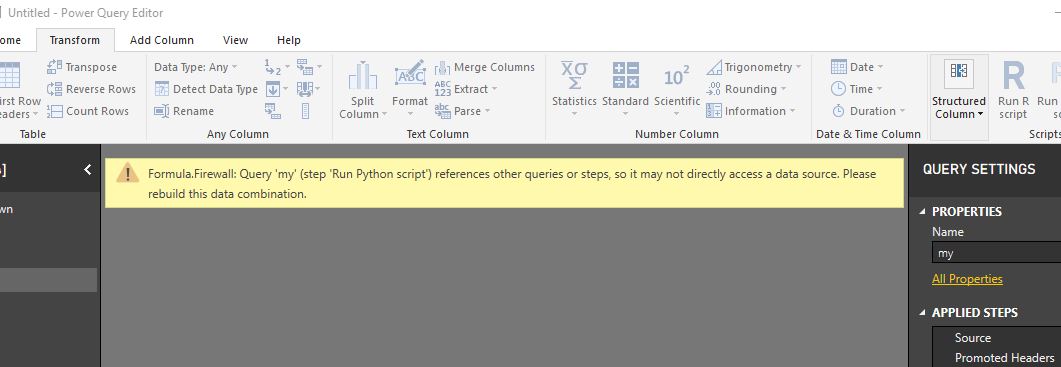
 Nota:
Nota: No en todos los casos funciona de igual manera. En el caso, por ejemplo, de que los datos cargados provengan de un conector de carpeta y se hayan fusionado al menos dos archivos es posible que no te pregunte por el nivel de privacidad. En ese caso te dará un error (Formula.Firewall error) (ver Fig.5). Si esto ocurre, debemos ir a la configuración e indicarlo manualmente (ver Fig.6) y por último refrescar (ver Fig.7).
4- Seguidamente, ejecutaremos otro script de Python (misma secuencia de pasos que el anterior) pero esta vez para agrupar la edad por intervalos y que sea mejor el análisis.
Basta con escribir el siguiente código.
import pandas as pd
import numpy as np
# bandas de edades
bins = [0, 8, 15, 18, 25, 40, 60, 100]
# Creo varios grupos de acuerdo a bandas de las edades
names = ['1', '2', '3', '4', '5', '6', '7']
# Sustituyo la edad por el grupo al que pertenece
dataset['Age'] = pd.cut(dataset['Age'], bins, labels = names)
Hasta este punto hemos realizado una serie de transformaciones para dejar nuestros datos listos para trabajar. Se debe tener muy en cuenta que después de ejecutar los scripts automáticamente, Power BI cambia el tipo de dato. Esto puede afectar en nuestro análisis, por tal motivo, es importante no perder de vista ese detalle y asegurarse siempre de que se ajusta con lo que deseamos.
Aplicar algoritmos de Machine Learning
Ahora vamos a implementar distintos algoritmos de aprendizaje supervisado y evaluar la precisión de cada uno de ellos en los dos conjuntos de datos.
En el mundo del
Machine Learning no existe un algoritmo único que funcione siempre mejor que los demás para resolver un problema. Por eso que he hecho pruebas con distintos algoritmos, tales como: Regresión logística, Vecinos más cercanos, Árboles de decisión, Naibe Bayes Gaussiano.
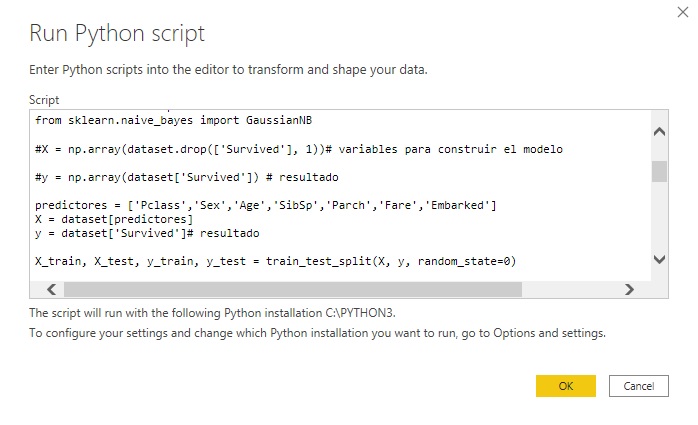
1- Muestro el código íntegramente.
# Se importan las librerias necesarias
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
# variables para construir el modelo, sirven para predecir el resultado
predictores = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
X = dataset[predictores]
# resultado variable objetivo
y = dataset['Survived']
#Separo los datos de "train" en entrenamiento y prueba para probar los #algoritm#os
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
#Regresión logística
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
print('Precisión Regresión Logística conjunto entrenamiento: {:.2f}'.format(logreg.score(X_train, y_train)))
print('Precisión Regresión Logística conjunto test: {:.2f}'.format(logreg.score(X_test, y_test)))
#K neighbors
knn = KNeighborsClassifier(n_neighbors = 9)
knn.fit(X_train, y_train)
print('Precisión K-NN(Vecinos más cercanos) conjunto entrenamiento: {:.2f}'.format(knn.score(X_train, y_train)))
print('Precisión K-NN(Vecinos más cercanos) conjunto test: {:.2f}'.format(knn.score(X_test, y_test)))
#Arboles de decisión
arb = DecisionTreeClassifier()
arb.fit(X_train, y_train)
print('Precisión Arboles de decisión conjunto entrenamiento: {:.2f}'.format(arb.score(X_train, y_train)))
print('Precisión Arboles de decisión conjunto test: {:.2f}'.format(arb.score(X_test, y_test)))
#Naibe Bayes Gaussiano
gau = GaussianNB()
gau.fit(X_train, y_train)
print('Precisión Naibe Bayes Gaussiano conjunto entrenamiento: {:.2f}'.format(gau.score(X_train, y_train)))
print('Precisión Naibe Bayes Gaussiano conjunto test: {:.2f}'.format(gau.score(X_test, y_test)))
#Ya teniendo nuestros modelos procedemos a realizar la predicción #respectiva utilizando la data de prueba.
#Selecciono el modelo de regresión logística
y_pred = logreg.predict(X) #se guarda la predicción
y_prob = logreg.predict_proba(X) #se guarda la probabilidad
#añadir los resultados en dos nuevas columnas (predicción, #probabilidad)
dataset['Prediccion'] = y_pred
dataset['Probabilidad Supervivencia'] = y_prob[:,1]
Aunque no sea el algoritmo que más precisión nos otorga en la resolución de nuestro problema, he decidido usar el de la Regresión Logística. Este algoritmo es uno de los más utilizados en la resolución de problemas de clasificación pues nos devuelve la probabilidad como valor entre 0 y 1.
Dicho algoritmo es extremadamente útil en casos como este, ya que no solo podremos saber la probabilidad de supervivencia, sino por el contrario, la probabilidad de que muera la persona.
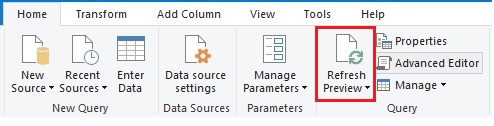
2-Una vez tenemos todo el código listo para ejecutar, lo pegamos en la ventana de Scripts de Python del editor de consultas y ejecutamos (ver Fig.8).
 Nota:
Nota: Recomiendo crear scripts independientes del código que se va a utilizar para probar y depurar cualquier problema antes de usarlo en Power BI.
En mi caso uso Visual Studio Code, pero también podemos usar Notebook, Pysharms, Visual Studio... Esto dependerá del entorno de desarrollo que tengáis montado ya que los mensajes de error proporcionados por Power BI no siempre son tan informativos.
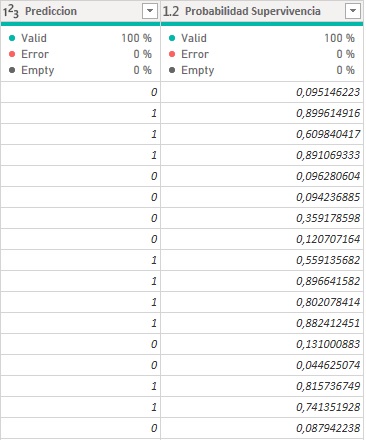
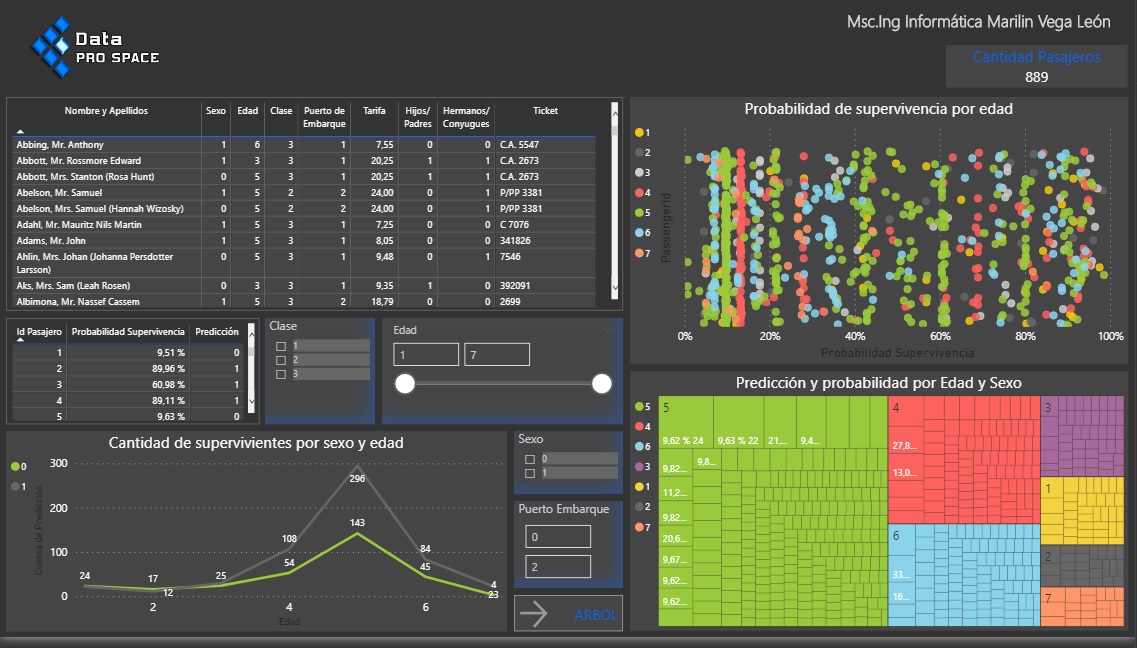
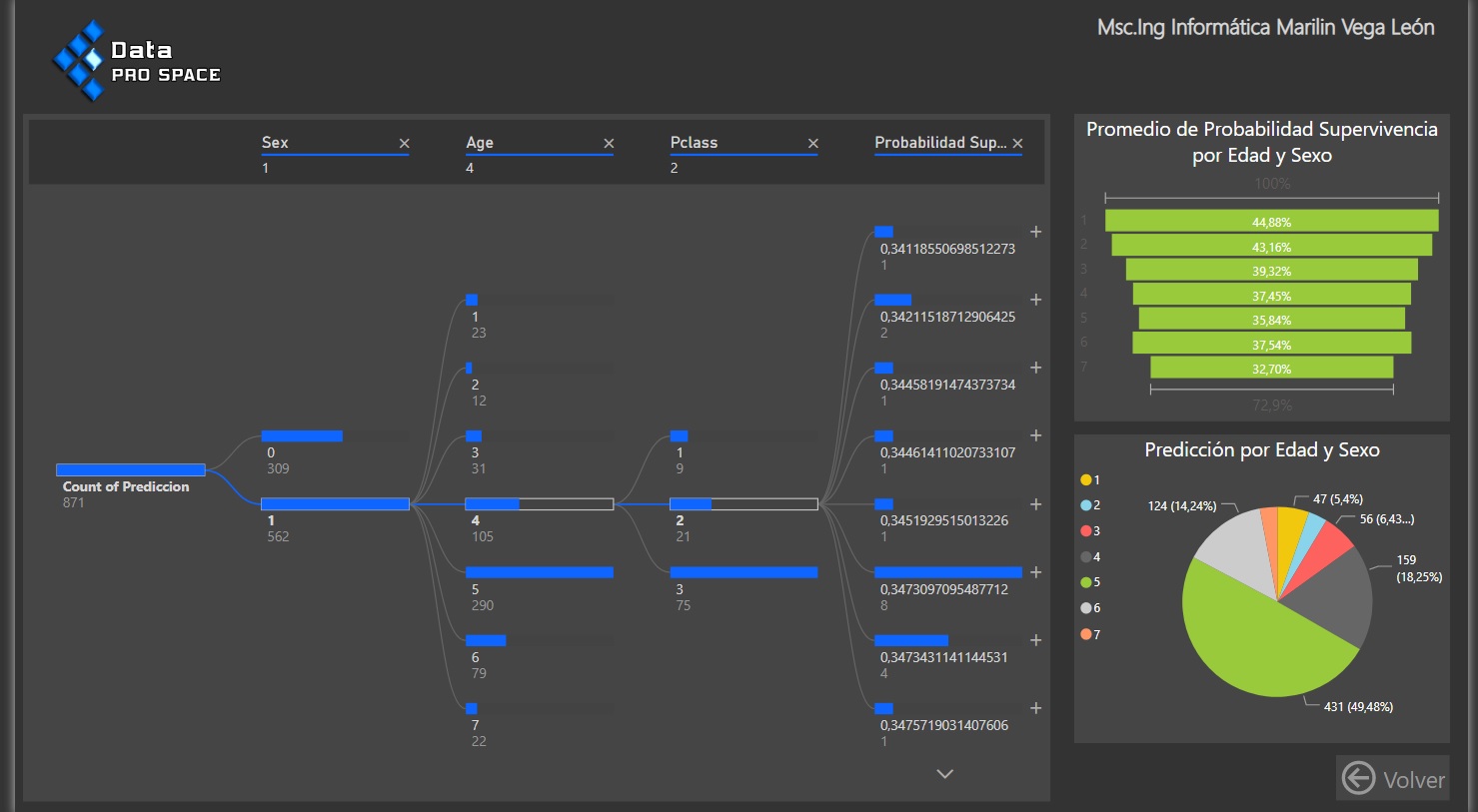
3-Finalmente obtendremos la información deseada como se muestra en la siguiente figura (ver Fig.9).
 Nota:
Nota: Cada vez que actualicemos nuestras consultas, el Script de Python se ejecutará, por lo que tendremos la capacidad de filtrar y segmentar estas columnas introducidas de la misma manera que cualquier otra información presente en nuestro modelo de datos.
4- Finalmente, podemos visualizar dicha información en nuestros informes, dotándolos esta vez de aplicaciones de
Machine Learning capaces de resolver problemas de clasificación y regresión utilizando múltiples algoritmos, que podremos aplicar en una gran variedad de situaciones dentro del mundo empresarial.
En futuros artículos profundizaré aún más en el tema del
Machine Learning, así que atentos a futuros post :) .